
Machine Learning Algorithms
Machine learning algorithms are data analysis methods which search data sets for patterns and characteristic structures. Typical tasks are the classification of data, automatic regression and unsupervised model fitting. Machine learning has emerged mainly from computer science and artificial intelligence, and draws on methods from a variety of related subjects including statistics, applied mathematics and more specialized fields, such as pattern recognition and neural computation. Applications are, for example, image and speech analysis, medical imaging, bioinformatics and exploratory data analysis in natural science and engineering:
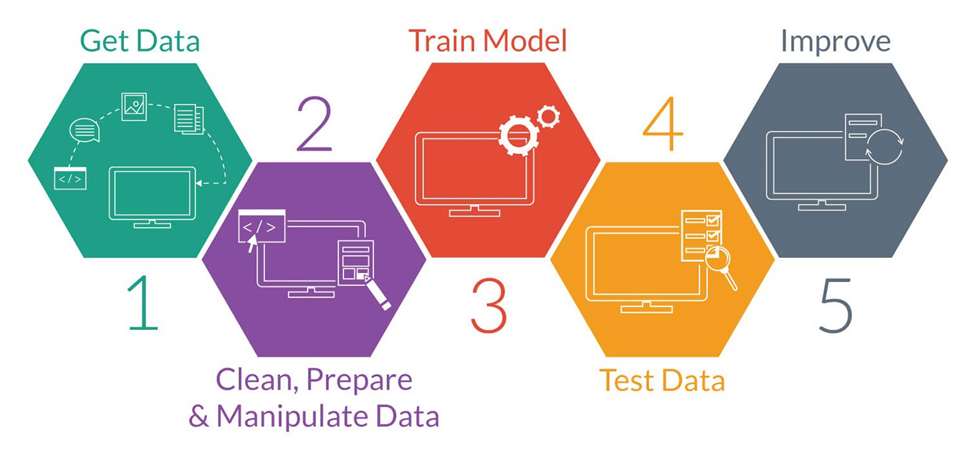
Machine Learning is the construction of algorithms that learn from and respond to large datasets faster and make effective predictions. It instructs computers to find patterns in data without being explicitly programmed and provides ‘high-value predictions that can guide better decisions and smart actions in real time without human intervention’. While the concept of Machine Learning has been around for a long time, the ability to automatically apply complex mathematical calculations to big data – ceaselessly and quickly – is gaining strength only in recent times.
Today, Machine Learning is the top skill in-demand globally amongst programmers, with a 2000% growth since 2015. Today’s demand for expertise in Machine Learning far exceeds the supply, and this imbalance will become more severe over the coming decade.
The ultimate aim of machine learning is to enable software applications to become more accurate without being explicitly programmed. But how do machines actually learn? The basic premise of machine learning is to build algorithms that can receive vast amounts of data, and then use statistical analysis to provide a reasonably accurate outcome.
Machine-learning algorithms are usually defined as supervised or unsupervised. Supervised algorithms need humans to provide both input and the desired output, in addition to providing the machine with feedback on the outcomes during the training phase. Once training is complete, the algorithm will apply what was learned to new data. Unsupervised algorithms do not need to be trained with desired outcome data. Instead, TOSALL use an iterative approach called deep learning to review data and arrive at conclusions.
In reality, machine learning is about setting systems to the task of searching through data to look for patterns and adjusting actions accordingly. For example, Recorded Future is training machines to recognize information such as references to cyberattacks, vulnerabilities, or data breaches. In this case, the machinery isn’t necessarily performing a task that is difficult for a human, but is impossible for a human to perform at the same scale.
Deep learning (deep neural networks)
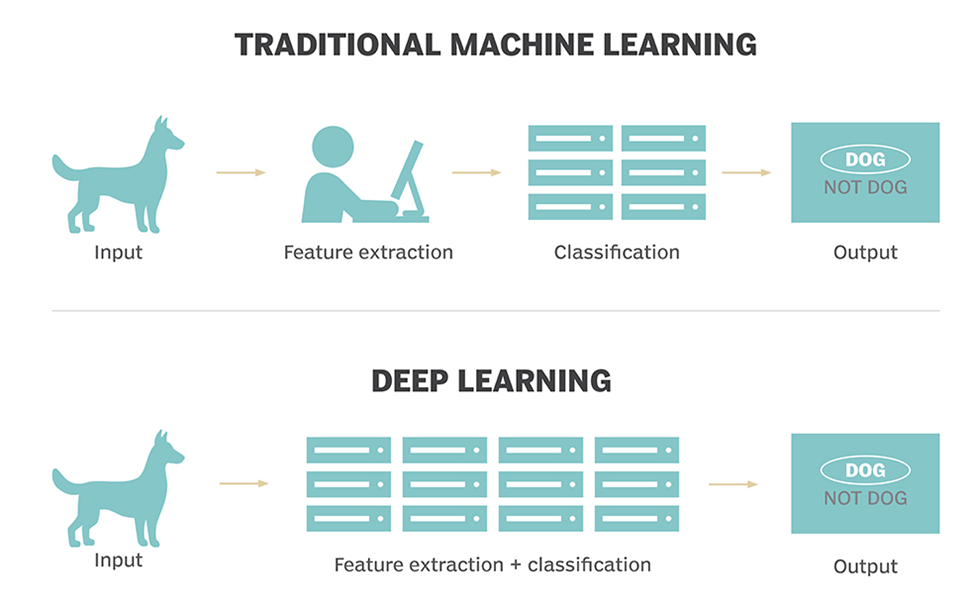
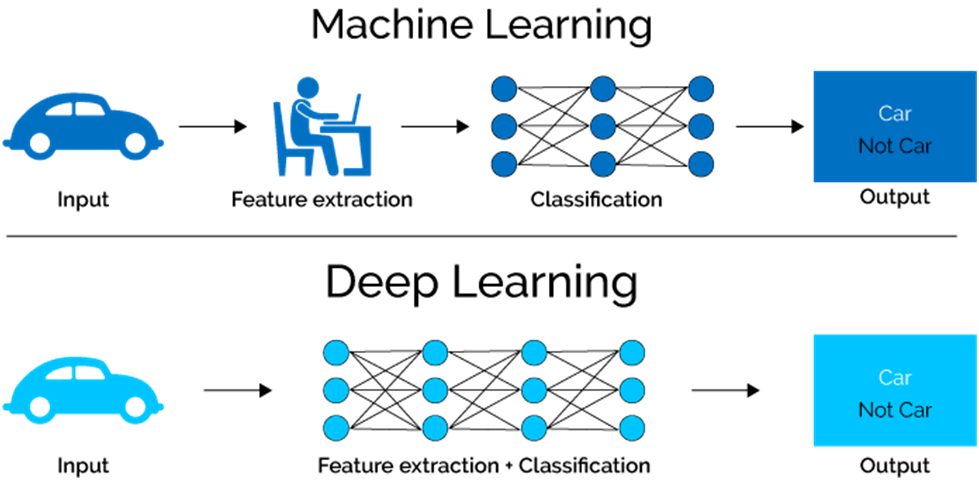
Deep learning is an aspect of artificial intelligence (AI) that is concerned with emulating the learning approach that human beings use to gain certain types of knowledge. At its simplest, deep learning can be thought of as a way to automate predictive analytics.
While traditional machine learning algorithms are linear, deep learning algorithms are stacked in a hierarchy of increasing complexity and abstraction. To understand deep learning, imagine a toddler whose first word is “dog.” The toddler learns what is (and what is not) a dog by pointing to objects and saying the word “dog.” The parent says “Yes, that is a dog” or “No, that is not a dog.” As the toddler continues to point to objects, he becomes more aware of the features that all dogs possess. What the toddler does, without knowing it, is to clarify a complex abstraction (the concept of dog) by building a hierarchy in which each level of abstraction is created with knowledge that was gained from the preceding layer of the hierarchy.
Computer programs that use deep learning go through much the same process. Each algorithm in the hierarchy applies a non-linear transformation on its input and uses what it learns to create a statistical model as output. Iterations continue until the output has reached an acceptable level of accuracy. The number of processing layers through which data must pass is what inspired the label “deep.”